AI是繪圖大師、也是物理模擬專家! —— 使用擴散模型來快速生成偵測器模擬資料

大家有沒有用過「AI繪圖」工具呢?短短幾年之內,繪圖就可以不使用紙筆、也不使用電腦繪圖軟體與繪圖板的組合,而是在網站上下一連串的「神奇咒語」,等個幾十秒鐘就把一張又一張栩栩如生的照片等級影像生成出來?如果使用特定的AI模型,還可以指定模仿各家各派大師的作畫風格,就算是二次元動漫角色也可以簡單的產生。突然之間電腦繪圖從需要大量練習作畫,變成人人可以做到的「簡單」工作。當然與這些工具普及隨附而來的問題也造成不少的爭議,最常見的問題就是「版權」。因為AI繪圖並非無中生有,而是使用大量現成影像資料交付給各種生成網路模型才訓練出來;也就是說AI繪圖也可以說是一種「臨摹」,那產生的影像版權到底是屬於誰的呢?
這種利用AI演算法來進行圖像生成的技術其實不是突然誕生出來的。早期就有所謂的「生成對抗網路」(Generative adversarial network, GAN) [1],利用兩組神經網路互相「較勁」,一組負責生成圖像、另外一組負責分辨真假圖形。訓練完成後就可以隨機產生圖像,尤其常被拿來生成「其實不存在」的人類頭像。而今天圖像生成演算法已經改進成所謂的「擴散模型」(Diffusion model) [2] 新方法了。 擴散模型的基本設計是一個雙向的「演化」:一邊是逐漸把完整的圖像,逐步根據常態分佈加入雜訊,最後變成一團看不出所以然的雜訊圖形;另外一個方向則是訓練網路模型降噪,去除隨機雜訊,逐漸變回完整的圖像。已訓練完成後的網路模型就可以拿來進行圖像生成,從一團隨機雜訊,逐步的變化成有意義的圖像,最後可以生成高解析度的圖像。經常被提及的AI圖像生成工具,如Midjourney [3]、Stable diffusion [4],基本上都是利用類似的架構來運作的,就如圖一所展示的「成果」。
那這些圖像生成技術難道只能用來產生影像,然後讓一部分的繪圖工作者失業嗎?其實不然。這些工具的重點在於「簡單快速」生成「以假亂真」的資料––那我們是不是可以把這個技術拿來運用其他地方呢?比如說,在高能物理實驗裡,為了要量測物理反應所產生的高能量粒子,通常得倚賴建造巨大且複雜的偵測器,就如一台複雜的相機一樣。但是高能量粒子到底會在偵測器裡留下怎樣的訊號,好讓科學家反推高能量粒子的物理性質,其實得要倚賴大量的「偵測器模擬資料」,也就是得要計算這些粒子當穿過偵測器材料時所發生的連鎖反應。這些計算通常是一個非常消耗計算資源的過程,這些高能量粒子不只會在自身穿入偵測器材料裡後留下一部分能量,同時也有很大的機會誕生許多的次級粒子,繼續在偵測器結構裡留下更複雜的圖像。要完整的模擬高能量粒子與偵測器反應是非常緩慢的,但如果改用「擴散模型」,是不是就可以輕鬆愉快的產生大量的模擬資料?
我們接下來就來討論我們如何利用擴散模型來產生高能實驗裡的偵測器模擬資料吧!相對於一般影像生成,產生模擬資料則更會因為得要遵守一些物理特性的細節而非常具有挑戰性,就讓我們逐一道來。如果對我們如何在高能實驗裡使用各式各樣的AI、或是機器學習演算法,可以參照2022年四月份物理雙月刊「當高能粒子撞上機器學習」一文 [5]。

圖一:利用各家各派的AI圖形生成工具產生的「大強子對撞機」(Large Hadron Collider)圖片。即使下的生成指令完全一樣,但生出來的圖形風格各異。
傳統的偵測器模擬資料生成方式
在高能物理實驗中,偵測器模擬是不可或缺的一環,由於研究目標是小至夸克等級,每次實驗對撞時,總是有數以萬計的次原子粒子參與反應。因此若是不透過模擬根本無法確定實際資料到底包含哪些粒子,彼此的反應又是如何。因此研究人員依賴這些模擬數據來理解粒子在偵測器中的行為、校正實驗數據,並開發信號處理和重建算法。這些模擬需要非常精確地再現粒子與偵測器材料之間的複雜相互作用,而這通常依賴於蒙特卡羅 (Monte Carlo) 方法與物理模擬軟件,如著名的GEANT4 [6]。
GEANT4 是一種廣泛使用的工具,用於模擬粒子與物質的相互作用。它基於物理模型來模擬粒子的傳播、能量沉積、散射和次級粒子的產生。就如圖二所示,這些模擬高度準確,但同時也非常耗費計算資源。一些高能物理實驗,如大型強子對撞機(LHC)所使用的 ATLAS 和 CMS 偵測器,可能需要生成數以千萬計的事件,來支持物理分析與系統校正。這導致模擬工作成為一個計算瓶頸,因為每個事件的模擬可能需要數分鐘的計算時間。而每次分析總是有數以萬計的事件,這意味著需要花幾個月的時間等待模擬結果。甚至若考慮到日後對撞機的擴建與升級,時間將進一步拉長到難以等待的長度,因此我們必須想辦法找到合適的替代方案。

圖二:使用GEANT4來模擬一顆帶有100GeV能量的中子,打入CMS實驗次世代高解析量能器(High-granularity Calorimeter, HGCAL)的部分模型。可以看到有非常大量的次原子粒子如光子、電子等,藉由核子反應連鎖產生。這樣的模擬必然需要大量的計算資源才能運作。
近年來,為了解決這一問題,出現了一些針對模擬加速的嘗試。例如,CaloChallenge [7] 是一個針對能量量測模擬的社群挑戰,旨在通過機器學習技術來提升模擬效率。這些方法嘗試在計算效率與物理精度之間取得平衡。然而,這些技術仍然面臨著模型穩定性、物理一致性和數據擴展性等挑戰。
總而言之,傳統的模擬方法雖然精確,但計算資源的限制成為高能物理實驗的一大挑戰。這為探索新型生成技術,如擴散模型,提供了廣闊的空間。
引入擴散模型進行資料生成
擴散模型是一種新興的生成技術,近年來在圖像生成、語音合成等領域取得了突破性進展。這種架構的關鍵優勢在於它的生成能力具有穩定性和靈活性。與生成對抗網絡(GANs)相比,擴散模型的訓練過程更加穩定,且更容易控制生成數據的特性,並且不需要耗費時間訓練兩個模型。因此,擴散模型成為高能物理模擬數據生成的一個有力的候選演算法。
那到底什麼是擴散模型呢?他的核心精神是這樣的,想像我們要生成一張圖片,最一開始的時候我們其實什麼都沒有,可能只有一個「我要生成一張狗圖片」的指令,所以這個時候一開始能有的其實就只有一堆隨機生成的雜訊圖片(就是像大家看到電視壞掉的那種圖片!)。那為了讓我們的模型學習如何從雜訊圖片逐步產生清晰圖片,訓練方法就是拿一張真正的狗的圖片,然後逐步加入雜訊,所以此圖片就會漸漸模糊直到最後完全就是一張只有雜訊的圖。而在過程中,每加一點點雜訊就讓模型去猜測剛剛加進去的雜訊是什麼。如此反覆之後,模型就可以學到每次加完雜訊後的變化是什麼。那如果模型知道一張真正的圖片是怎麼變成雜訊的,那是不是只要完全反著做就可以從雜訊生成一張圖片呢?這就是目前許多圖片生成式AI所使用的技巧,就如圖三所示!
那放在高能物理的資料生成裡呢?其實也是一模一樣的道理。以先前提到的CaloChallenge為例,要產生在每個離散空間點上的能量,也可以把他想像成是要產生一張有顏色的3D圖片,而顏色則代表著該點的能量,如圖四。我們將GEANT4模擬出來的偵測器資料,逐漸加入雜訊、最後變成在三維空間中離散的完全雜訊。使用擴散模型學到每次加完雜訊後的變化是什麼,然後進行反向操作、就可以將雜訊逐漸收束成符合物理學的模擬資料。也就是我們可以利用相同的技巧來,產生模擬結果所對應的「圖片」,進而幫助高能實驗加速分析囉!
測試比較與擴散模型的限制
就目前的測試結果顯示,擴散模型在數據「生成速度」方面具有顯著優勢。在同等硬體運作條件下,傳統模擬下生成單個事件需要數秒至數分鐘,而使用擴散模型僅需數毫秒至數十毫秒,實現了數百倍的加速!結果而言算是還不錯的,但對於要到達像GEANT4這樣的精準程度仍有好一段距離。如圖五的能量分佈圖為例,該圖左側是GEANT4模擬,右側則是我們使用擴散模型的模擬結果,大致上來說還算相似,每個區間的誤差都在50%以內。在只使用機器學習領域來複製模擬資料之下,已算是相當相似的結果了!畢竟每次實驗總是有一堆粒子與交互作用發生、也就是資料點與資料點之間其實是有關聯性的。但是對於只看到最後粒子在偵測器下留下能量分佈的模型來說,還是太難以發現其中彼此的連結、甚至是學到任何物理了。所以只能慢慢統整、慢慢地猜測。
相對之下,雖然人臉、或是貓狗多樣性很豐富,但由於所需要學習的關聯都在圖片上了(比如要學習到有兩個眼睛,鼻子在中間等等),而且不像高能資料那麼空洞、能量尺度可以差到好幾個數量級,因此也許對AI模型來說是相對容易學習的。另外還有一個問題,雖然使用機器學習的方法已經比傳統方法快很多了,但擴散模型事實上是屬於精準度高但還是相當耗時的模型,因此若是要產生高畫質的圖片,仍需要等待一段時間,或是耗費大量運算資源才能達成,這也是下一階段大家正在努力的方向。
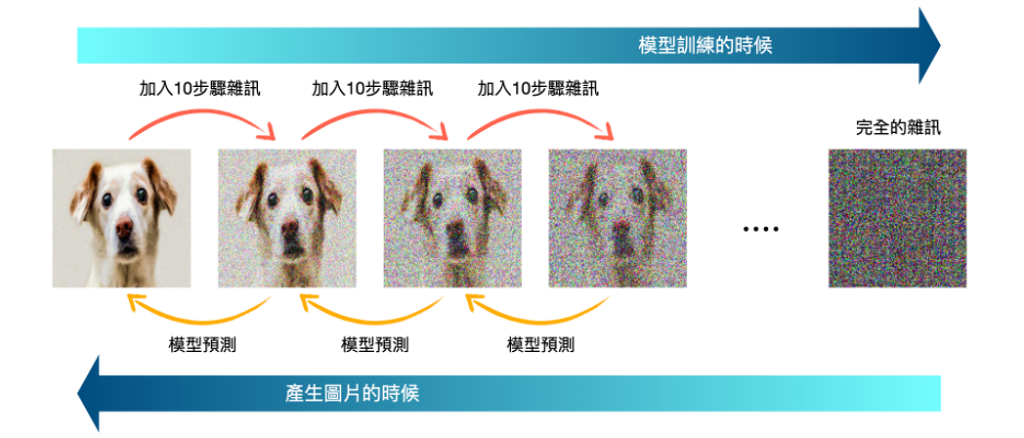
圖三:擴散模型的示意圖。將一張真正的狗狗圖片加入雜訊,並讓模型學習,想要產生圖片的時候就可以讓模型預測一步一步預測該如何自己產生狗的圖片。(該圖僅為展示,真實情況生成的圖片不會一模一樣。)
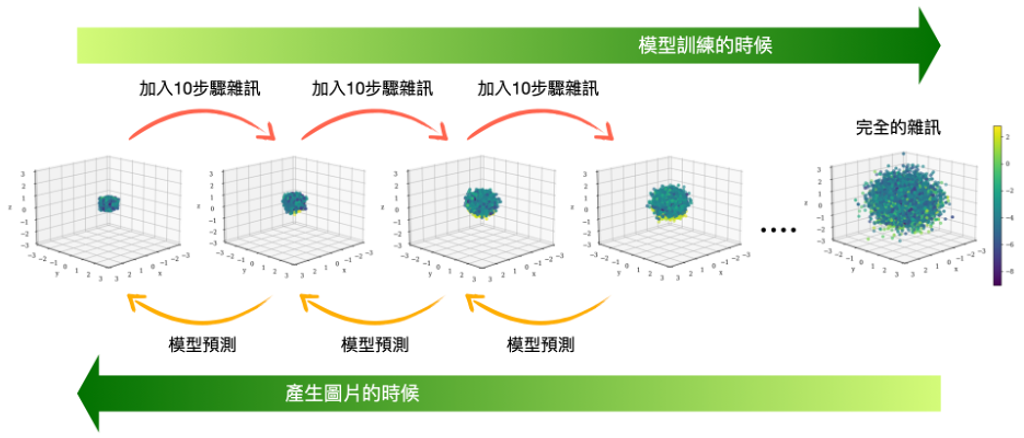
圖四:此為擴散模型在高能物理的應用,顏色為相對能量高低。可以把所有連鎖反應的點集合起來當成一張圖片,因此也可以運用和圖三一樣的邏輯來生成圖片,也就等於產生了我們所要模擬的數據。如圖可看到模型應學習大部分的點應該是集中於中心,而非如同雜訊一般大範圍散佈於偵測器上。
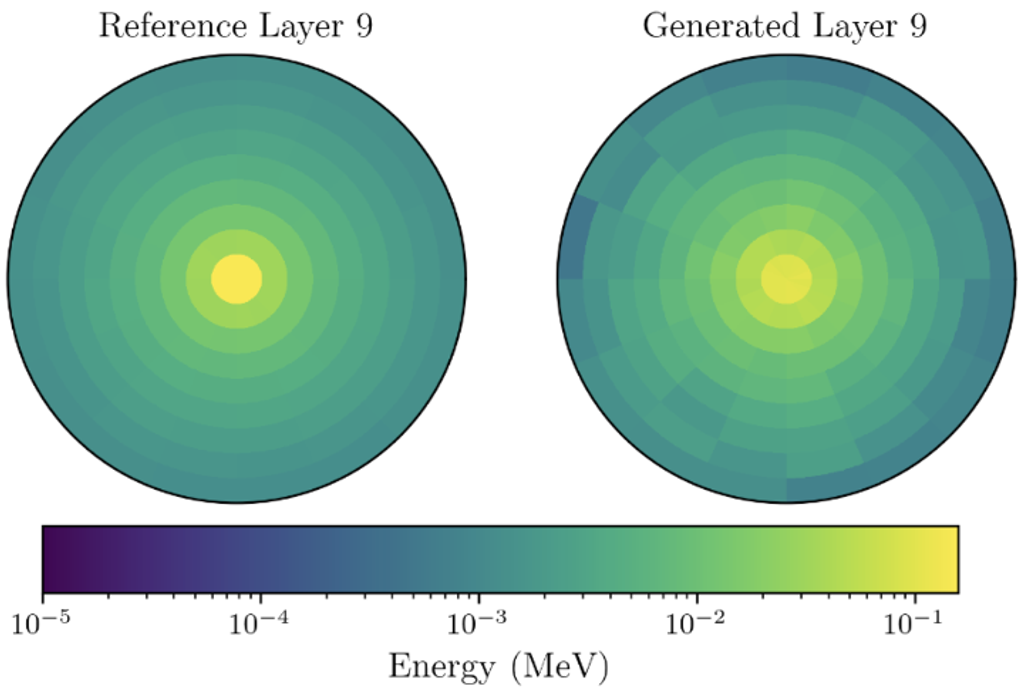
圖五:左側是GEANT4 模擬能量分佈圖,右側則是利用擴散模型所生成的模擬結果。如果只以數量級來看,已經是個相當好的成果了。然而細部仍然有不小的差距,待我們持續改進。
未來展望
總之,考慮到類神經網路在1980年之後才開始逐漸興起,更不用提更近期的深度學習、生成式模型等等,其實AI能有目前的能力已算是相當「爆炸性」的成長了。期待在未來,隨著運算資源的提升,以及機器學習理論的進步,肯定能達成現在意想不到的成果。而對在高能實驗物理運用AI而言,現在有一些大家想前進的方向:
- 擴展到更複雜的模擬場景:若未來擴散模型的精準度進一步提升,再加上對撞機升級與擴建導致GEANT4無力應付時,就不得不仰賴擴散模型作為模擬工具,或是利用「混種」的演算法來進行:比如說主要的物理模擬還是倚賴傳統方法、但是一些比較不重要的細節可以倚賴AI來補足。就如已有AI工具可以擴充照片、或是替影片補幀一樣。
- 物理約束的深度集成:目前的機器學習在絕大多數情形下仍然屬於「黑盒子」,即使結果精準,但仍難以得知中間到底發生了什麼事情。所以目前仍然有許多人致力於了解模型中的參數意義,希望了解AI模型到底學到了什麼方程式、甚至期待從中間找出從所未見的新物理知識!
- 多目標模型間的整合:目前的大部分的模型還都只能用於單一功能,所以我們需要訓練許多模型用以應付各種場合,比如要計算能量的時候需要用一個模型;但如果想產生其他物理量的時候又需要特別訓練模型專注於產生該物理量。因此目前也有許多人希望能訓練一個「通用模型」,他可以自己判斷現在的任務是什麼,並且用相對應的方法來進行模擬。
參考資料
- I. Goodfellow, J. Pouget-Abadie, M. Mirza, et al, “Generative Adversarial Nets”, Proceedings of the International Conference on Neural Information Processing Systems (NIPS 2014).
- Z. Chang, G. A. Koulieris, H. Shum, “On the Design Fundamentals of Diffusion Models: A Survey”. arXiv:2306.04542 (2023).
- Midjourney, https://www.midjourney.com/home
- “Stable diffusion - Generative Models by Stability AI”, https://stability.ai/
- 陳凱風, “當高能粒子撞上機器學習”, 物理雙月刊 2022年四月.
- S. Agostinelli et al. (GEANT4 Collaboration), “GEANT4 - A Simulation Toolkit”, Nucl. Instrum. Meth. A 506, 250-303 (2003), doi:10.1016/S0168-9002(03)01368-8
- Fast Calorimeter Simulation Challenge 2022, https://calochallenge.github.io/homepage/

